JGlossator
Contents
Overview
You may use JGlossator to create a gloss for Japanese text complete with de-inflected expressions, readings, audio pronunciation, example sentences, pitch accent, word frequency, kanji information, and grammar analysis.
JGlossator will automatically gloss any Japanese text that you copy to the clipboard. Setting aside more obvious usage, this makes it ideal for use with Capture2Text when reading manga or with AGTH/ITH when either playing visual novels or watching video with Japanese subtitles.
By right-clicking on a glossed entry you will be presented with a menu that allows you to view alternate entries, save the current entry to file, or listen to an audio pronunciation. You may hover over a Japanese word to see a Rikaichan-style popup.
JGlossator is highly configurable and allows you to modify many of the default behaviors and settings. For example, you can turn off the clipboard monitor, change themes, specify a new save format, remove pitch accent, etc. Just press the options button on the far right.
Type in an English word to search definitions instead. The resulting list will
be sorted based on frequency. To search whole words only, add "w/" in front
of the word. To use a regular expression, type "r/" followed by a regular
expression.
Kanji search is supported as well. Just use one of these formats:
| Search Based On | Format |
|---|
| Meanings | km/<comma-separated list of meanings> (Example: km/dragon) |
| RTK Primitives | kp/<comma-separated list of RTK primitives> (Example: kp/rain,eel) |
| Radical meanings | kr/<comma-separated list of radical meanings> (Example: kr/heart,moon,sword) |
| ON readings | ko/<comma-separated list of ON readings> (Exampe: ko/ねん) |
| KUN readings | kk/<comma-separated list of KUN readings> (Exampe: kk/こころ) |
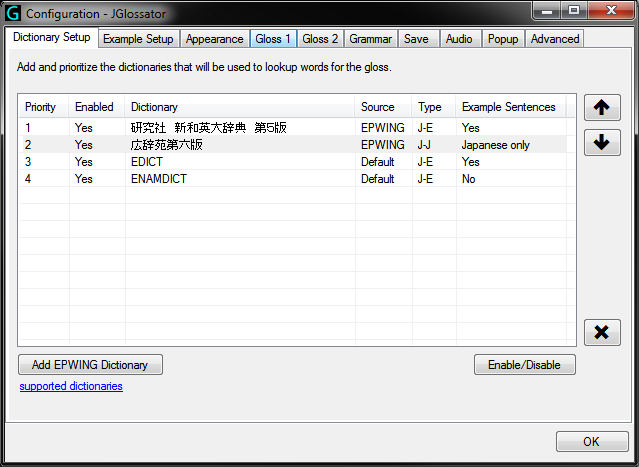
You can also perform a gloss using your favorite EPWING dictionaries. Just add them to the Dictionary Setup tab of the Options dialog.
Know basic HTML/CSS? Want to change a font, color, or maybe even the format of the kanji gloss? No problem, just create a new theme in the themes directory or modify an existing one.
Some useful shortcut keys:
| ESC | Place cursor in the input box |
| Up | (when the input box has focus) Clear text in the input box |
| Backspace | (when the input box doesn't have focus) Go back through the history |
| Ctrl-Up | Go back through the history |
| Ctrl-Down | Go forward through the history |
Download
The latest version may be found on the JGlossator download page hosted by SourceForge. The source code is also available at this link.
Installation
- Make sure that you have .Net Framework Version 3.5 installed (you probably
already do). If not, you can get it through Windows update or via the Microsoft website
- Unzip JGlossator. Make sure that there are no non-ASCII (ex. Japanese) characters in the JGlossator path. Also don't place JGlossator in Program Files due to write permission issues.
- In the unzipped directory, simply double-click JGlossator.exe to launch JGlossator.
Screenshots
- The main interface (showing two of the themes available):
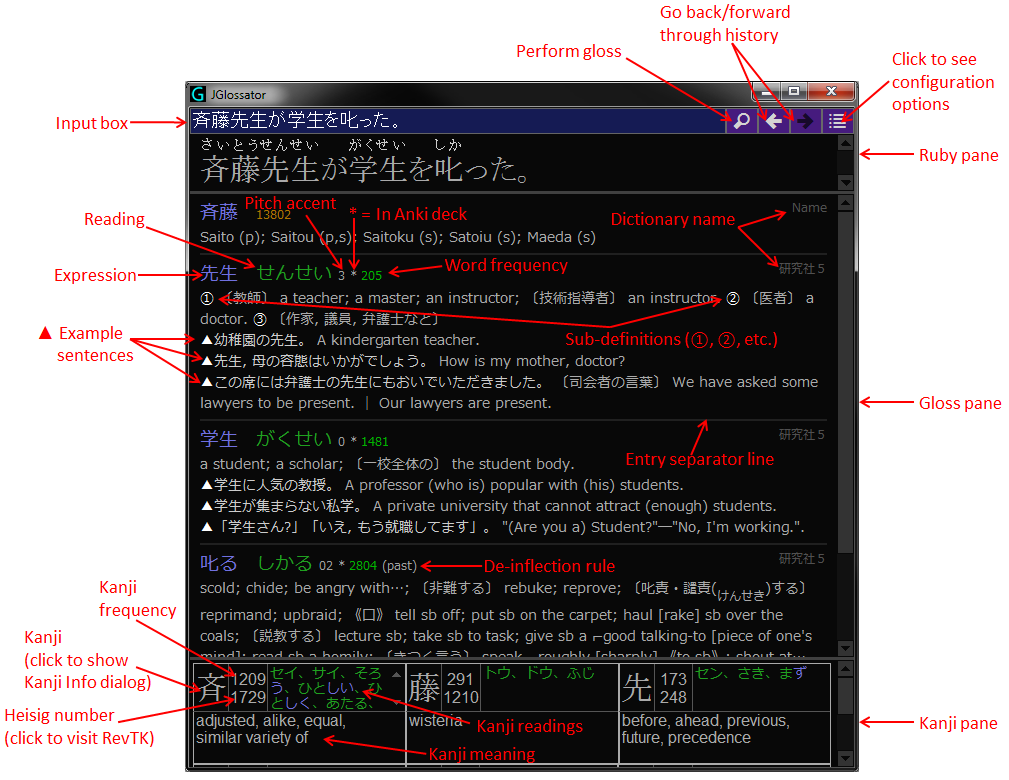
- The main interface (annotated):
- Right-click menu for an entry (annotated):


- Rikaichan-style popup when hovering over Japanese words:

- Configuration button menu (annotated):

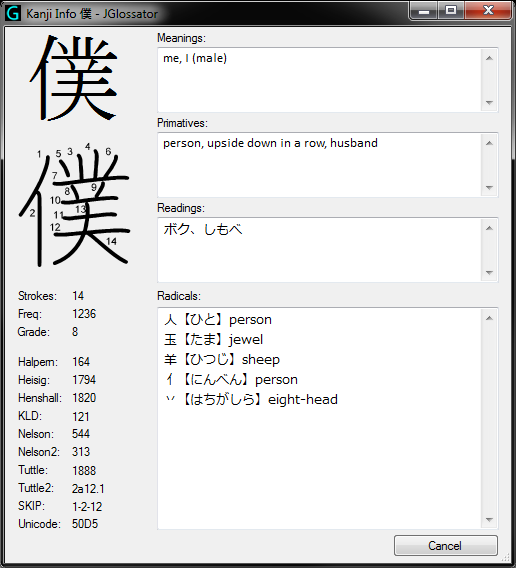
- Kanji Info dialog (click a kanji in the Kanji pane to display):
- Grammar pane (annotated) (To enable: Options -> Appearance -> Show the grammar pane):

- Definition search. If the search text contains only English, the EDICT definitions will be searched instead of performing the normal gloss. Entries will be sorted by frequency. To search for whole words only, add "w/" in front or add a trailing space (example: "w/experiment" or "experiment "). To perform a regular expression search, add "r/" in front (example: "r/exp\w*?l"). Screenshot:

- Kanji search. In this screenshot we search for all kanji containing the primitives "person" and "ten". The kanji are sorted based on number of strokes and then by frequency.

- Dictionary Setup tab from the Options dialog:
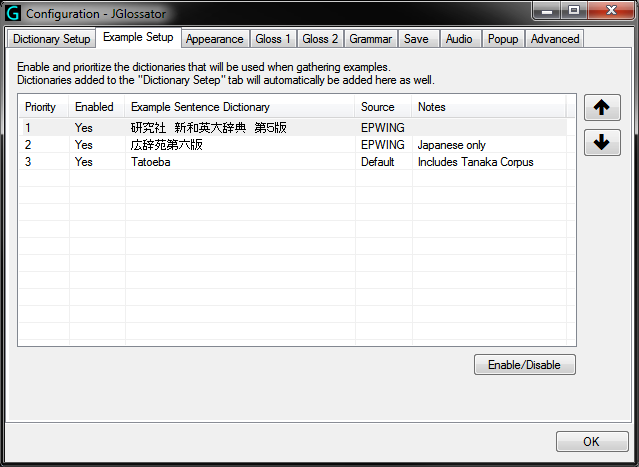
- Example Setup tab from the Options dialog:
- Appearance tab from the Options dialog:
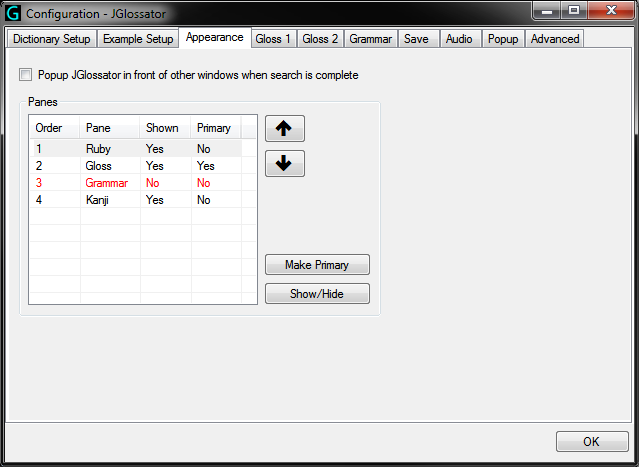
- Gloss 1 tab from the Options dialog:
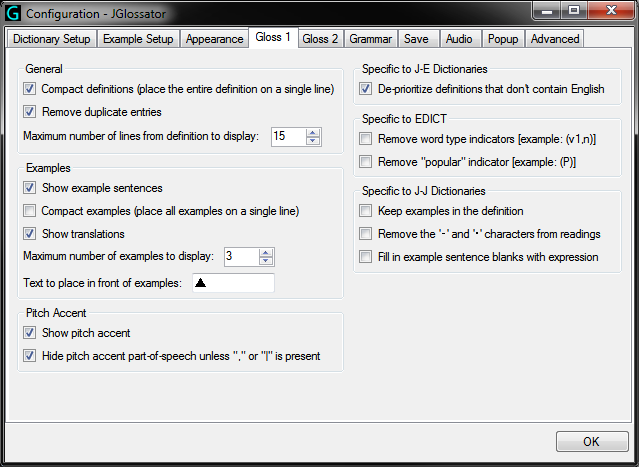
- Gloss 2 tab from the Options dialog:
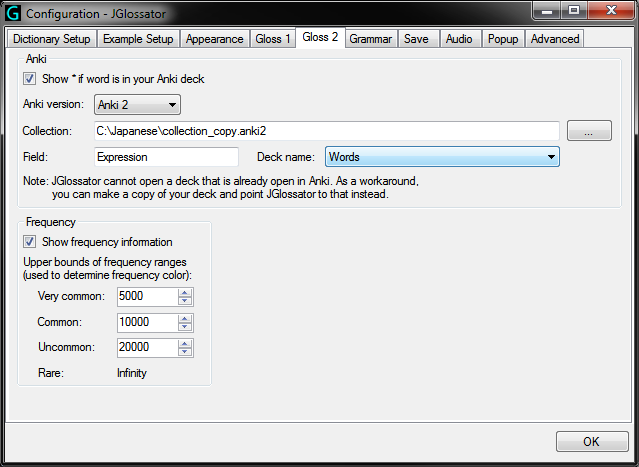
- Grammar tab from the Options dialog:

- Save tab from the Options dialog:
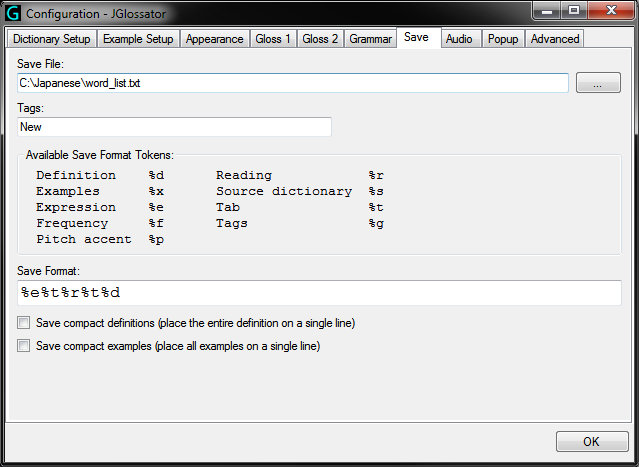
- Audio tab from the Options dialog:
- Popup tab from the Options dialog:
- Advanced tab from the Options dialog:

Blacklist
You may add the dictionary form of words that you would rather not see appear in the gloss to blacklist.txt (in the same directory as JGlossator.exe).
Word Frequencies
Most words will have a frequency number attached to them. This is the number of words that are more frequent than the given word + 1. So if this number is 700, it means that there are 699 words that are more frequent. The lower the number, the more frequent the word. Colors of the frequency numbers: very common words are green-ish, common words are yellow-ish, uncommon words are orange-ish, rare words are pink-ish. Frequencies are based on analysis of 5000+ novels. Naturally, frequency based on other mediums (such as newspapers) might vary. Not all words have frequency information.
Abbreviations
Part of Speech Marking
| adj-i | adjective (keiyoushi) |
| adj-na | adjectival nouns or quasi-adjectives (keiyodoshi) |
| adj-no | nouns which may take the genitive case particle `no' |
| adj-pn | pre-noun adjectival (rentaishi) |
| adj-t | `taru' adjective |
| adj-f | noun or verb acting prenominally (other than the above) |
| adj | former adjective classification (being removed) |
| adv | adverb (fukushi) |
| adv-n | adverbial noun |
| adv-to | adverb taking the `to' particle |
| aux | auxiliary |
| aux-v | auxiliary verb |
| aux-adj | auxiliary adjective |
| conj | conjunction |
| ctr | counter |
| exp | Expressions (phrases, clauses, etc.) |
| int | interjection (kandoushi) |
| iv | irregular verb |
| n | noun (common) (futsuumeishi) |
| n-adv | adverbial noun (fukushitekimeishi) |
| n-pref | noun, used as a prefix |
| n-suf | noun, used as a suffix |
| n-t | noun (temporal) (jisoumeishi) |
| num | numeric |
| pn | pronoun |
| pref | prefix |
| prt | particle |
| suf | suffix |
| v1 | Ichidan verb |
| v2a-s | Nidan verb with 'u' ending (archaic) |
| v4h | Yodan verb with `hu/fu' ending (archaic) |
| v4r | Yodan verb with `ru' ending (archaic) |
| v5 | Godan verb (not completely classified) |
| v5aru | Godan verb - -aru special class |
| v5b | Godan verb with `bu' ending |
| v5g | Godan verb with `gu' ending |
| v5k | Godan verb with `ku' ending |
| v5k-s | Godan verb - iku/yuku special class |
| v5m | Godan verb with `mu' ending |
| v5n | Godan verb with `nu' ending |
| v5r | Godan verb with `ru' ending |
| v5r-i | Godan verb with `ru' ending (irregular verb) |
| v5s | Godan verb with `su' ending |
| v5t | Godan verb with `tsu' ending |
| v5u | Godan verb with `u' ending |
| v5u-s | Godan verb with `u' ending (special class) |
| v5uru | Godan verb - uru old class verb (old form of Eru) |
| v5z | Godan verb with `zu' ending |
| vz | Ichidan verb - zuru verb - (alternative form of -jiru verbs) |
| vi | intransitive verb |
| vk | kuru verb - special class |
| vn | irregular nu verb |
| vs | noun or participle which takes the aux. verb suru |
| vs-c | su verb - precursor to the modern suru |
| vs-i | suru verb - irregular |
| vs-s | suru verb - special class |
| vt | transitive verb |
Field of Application
| Buddh | Buddhist term |
| MA | martial arts term |
| comp | computer terminology |
| food | food term |
| geom | geometry term |
| gram | grammatical term |
| ling | linguistics terminology |
| math | mathematics |
| mil | military |
| physics | physics terminology |
Miscellaneous Markings
| X | rude or X-rated term |
| abbr | abbreviation |
| arch | archaism |
| ateji | ateji (phonetic) reading |
| chn | children's language |
| col | colloquialism |
| derog | derogatory term |
| eK | exclusively kanji |
| ek | exclusively kana |
| fam | familiar language |
| fem | female term or language |
| gikun | gikun (meaning) reading |
| hon | honorific or respectful (sonkeigo) language |
| hum | humble (kenjougo) language |
| ik | word containing irregular kana usage |
| iK | word containing irregular kanji usage |
| id | idiomatic expression |
| io | irregular okurigana usage |
| m-sl | manga slang |
| male | male term or language |
| male-sl | male slang |
| oK | word containing out-dated kanji |
| obs | obsolete term |
| obsc | obscure term |
| ok | out-dated or obsolete kana usage |
| on-mim | onomatopoeic or mimetic word |
| poet | poetical term |
| pol | polite (teineigo) language |
| rare | rare (now replaced by "obsc") |
| sens | sensitive word |
| sl | slang |
| uK | word usually written using kanji alone |
| uk | word usually written using kana alone |
| vulg | vulgar expression or word |
Pitch Accents
What are pitch accents?
The following was taken from Wikipedia.
In standard Japanese (標準語 hyōjungo), pitch accent has the following effect on words spoken in isolation:
- If the accent is on the first mora, then the pitch starts high, drops suddenly on the second mora, then levels out. The pitch may fall across both moras, or mostly on one or the other (depending on the sequence of sounds)—that is, the first mora may end with a high falling pitch, or the second may begin with a (low) falling pitch, but a native speaker will hear the first mora as accented regardless.
- If the accent is on a mora other than the first or the last, then the pitch has an initial rise from a low starting point, reaches a near-maximum at the accented mora, then drops suddenly on the next.
- If the word doesn't have an accent, the pitch rises from a low starting point on the first mora or two, and then levels out in the middle of the speaker's range, without ever reaching the high tone of an accented mora. Japanese describe the sound as "flat" (平板 heiban) or "accentless".
Japanese accent is presented with a two-pitch-level model. In this representation, each mora (syllable) is either high (H) or low (L) in pitch, with the shift from high to low of an accented mora transcribed H*L.
- If the accent is on the first mora, then the first syllable is high-pitched and the others are low: H*L, H*L-L, H*L-L-L, H*L-L-L-L, etc.
- If the accent is on a mora other than the first, then the first mora is low, the following moras up to and including the accented one are high, and the rest are low: L-H, L-H*L, L-H-H*L, L-H-H-H*L, etc.
- If the word is heiban (doesn't have an accent), the first mora is low and the others are high: L-H, L-H-H, L-H-H-H, L-H-H-H-H, etc. This high pitch spreads to unaccented grammatical particles that attach to the end of the word, whereas these would have a low pitch when attached to an accented word.
Although only the terms "high" and "low" are used, the high of an unaccented mora is not as high as an accented mora.
Format of JGlossator's pitch accents:
<blank> - Example: 単眼鏡 たんがんきょう
No pitch accent information available for this word.
0 – Example: 洗う あらう 0
Zero means no accent. From Wikipedia: "Word doesn't have an accent, the pitch rises from a low starting point on the first mora or two, and then levels out in the middle of the speaker's range, without ever reaching the high tone of an accented mora. Japanese describe the sound as "flat" (平板 heiban) or "accentless". "
2 – Example: 願う ねがう 2
The "2" indicates that the accent is on the 2nd mora (the が).
32 – Example: 著作権 ちょさくけん 32
The "32" indicates that the accent can be on either the 3rd mora (く) or 2nd mora (さ). This is in frequency order, meaning that it is more common for the accent to be on the 3rd mora than the 2nd mora.
{11} – Example: 超越論的観念論 ちょうえつろんてきかんねんろん {11}
Curly braces are placed around pitch accents that are in the double digits. The "11" indicates that the accent is on the 11th mora.
21,0 – Example: 飛車 しゃ 21,0
For some words, the pitch accent dictionary contains multiple sub-definitions in an entry. Sometimes each sub-definition can have a different pitch. A comma separates the pitch accents for the multiple sub-definitions. The "21,0" means that in the 1st sub-definition of the word, the accent is on either the 2nd mora (しゃ) or 1st mora (ひ), and that in the 2nd sub-definition of the word, no accent is present.
1|Ø – Example: 朝日 あさひ 1|Ø
For some words, the pitch accent dictionary contains multiple entries that have identical expressions and readings. The "|" separates the pitch found in each entry. The "1" indicates that in the first entry, the pitch accent was on the first mora. The "Ø" symbol indicates that the other entry contained no pitch accent information.
1-2 – Example: 思案投げ首 しあんなげくび 1-2
I'm not sure what the "-" is supposed to represent. It is present in the pitch accent dictionary so I left it in.
3? – Example: 手投弾 てなげだん 3?
A trailing question mark is added to pitch accents that have a small chance of being inaccurate and have not yet been checked by a human.
(part-of-speech) – Example: 道道 みちみち (副)0,(名)2
Sometimes pitch accent changes depending on the word's part-of-speech. The part-of-speech is placed inside of parenthesis. The above example shows that the pitch accent is "0" when the word is used as an adverb and "2" when the word is used as a noun.
Valid part-of-speech options:
| (名) | 名詞 |
| (代) | 代名詞 |
| (動五) | 動詞五段活用 |
| (動五[四]) | 動詞口語五段活用・文語四段活用 |
| (動四) | 動詞四段活用 |
| (動上一) | 動詞上一段活用 |
| (動上二) | 動詞上二段活用 |
| (動下一) | 動詞下一段活用 |
| (動下二) | 動詞下二段活用 |
| (動カ変) | 動詞カ行変格活用 |
| (動サ変) | 動詞サ行変格活用 |
| (動ナ変) | 動詞ナ行変格活用 |
| (動ラ変) | 動詞ラ行変格活用 |
| (動特活) | 動詞特別活用 |
| (形) | 形容詞 |
| (形ク) | 形容詞ク活用 |
| (形シク) | 形容詞シク活用 |
| (形動) | 形容動詞 |
| (形動ナリ) | 形容動詞ナリ活用 |
| (形動タリ) | 形容動詞タリ活用 |
| (ト|タル) | 「~と」(副)「~たる」(連体詞)の形で用いられるもの |
| (連体) | 連体詞 |
| (副) | 副詞 |
| (接続) | 接続詞 |
| (感) | 感動詞 |
| (助動) | 助動詞 |
| (格助) | 格助詞 |
| (接助) | 接続助詞 |
| (副助) | 副助詞 |
| (係助) | 係助詞 |
| (終助) | 終助詞 |
| (間投助) | 間投助詞 |
| (並立助) | 並立助詞 |
| (準体助) | 準体助詞 |
| (接頭) | 接頭語 |
| (接尾) | 接尾語 |
| (連語) | 連語 |
| (枕詞) | 枕詞 |

